Solving the Terraform Backend Chicken-and-Egg Problem

Introduction
My preferred way to store Terraform state files is close to the provisioned infrastructure. In my case this is mostly Azure Blob Storage. This approach offers built-in benefits like RBAC, versioning, locking, and identity-based authentication, making it an excellent solution for state management at almost no cost.
However, there’s a catch: you need to create the storage account before Terraform can use it. This creates a chicken and egg problem - how do you provision the state storage using Terraform itself without manual steps or external scripts?
In this article, I’ll walk through a fully automated solution to deploy Terraform state storage in Azure Blob and import “self” state there, ensuring everything is managed declaratively from the start.
The Solution
The goal is to:
- Create the storage account and container using Terraform.
- Switch the Terraform backend to use the newly created storage - without manual intervention.
- Be able to manage the state storage then from CI/CD
NOTE: While this example focuses on Azure Blob, the same pattern applies to other backends like AWS S3 or GCS.
Step 1: Initial Setup
The initial operator (likely you or a service principal) needs permissions to:
- Create resources (Contributor, Owner).
- Assign RBAC roles (User Access Administrator, RBAC Administrator or Owner).
We’ll pass the operator’s object ID as a variable to grant storage account access during initial setup. You can retrieve this ID by executing az ad signed-in-user show --query id --output tsv command or automate retrieval in the terraform by using object_id output from data "azurerm_client_config" "current" {} datasource. I generally recommend against using such datasources since they trigger permission changes whenever the identity changes.
Step 2: Terraform Implementation
Variables and Providers Configuration
The following configuration establishes our foundation. We need to provide the subscription_id (mandatory for AzureRM >=4.0), the initial user ID as previously explained, and the environment name.
The environment parameter may not be necessary in all scenarios. However, if you’re implementing Terraform partial backend configuration with separate state storage for each environment (recommended practice), this will generate the appropriate configuration with consistent naming. If you are not using partial backend configuration, than you can remove this from template and move parameters from .tfbackend file to backend.tf file.
Setting storage_use_azuread to true configures storage to use Azure AD authentication rather than access keys. If you require access keys for specific use cases, you can remove this line and adjust the storage configuration accordingly.
variable "environment" {
description = "The environment name."
type = string
}
variable "initial_user_admin_object_id" {
description = "Object ID of the user/service principal setting up the backend."
type = string
}
variable "subscription_id" {
description = "The subscription ID to use"
type = string
}
provider "azurerm" {
features {}
subscription_id = var.subscription_id
storage_use_azuread = true
}
Storage Resources Provisioning
Now let’s provision the necessary storage resources. The account replication is set to ZRS because Poland Central region doesn’t support global redundancy. However, for production Terraform state storage, I strongly recommend using RA-GRS or at least GRS storage. The cost difference is negligible, but this additional redundancy provides protection for your state files in disaster scenarios.
In this section, we also assign the Storage Blob Data Contributor role to the initial operator, enabling container creation and state migration in subsequent steps.
resource "azurerm_resource_group" "this" {
name = "cloudchronicles-init-rg"
location = "polandcentral"
}
resource "azurerm_storage_account" "this" {
name = "${var.environment}initst"
resource_group_name = azurerm_resource_group.this.name
location = azurerm_resource_group.this.location
account_tier = "Standard"
account_replication_type = "ZRS"
shared_access_key_enabled = false
default_to_oauth_authentication = true
}
resource "azurerm_role_assignment" "blob_data_contributor_initial_user_admin" {
principal_id = var.initial_user_admin_object_id
role_definition_name = "Storage Blob Data Contributor"
scope = azurerm_storage_account.this.id
}
resource "azurerm_storage_container" "this" {
name = "tfstate"
storage_account_id = azurerm_storage_account.this.id
container_access_type = "private"
depends_on = [azurerm_role_assignment.blob_data_contributor_initial_user_admin]
}
Identity for managing state securely in CI/CD
The following resources establish secure programmatic access for CI/CD pipelines. If you’re not using CI/CD for infrastructure management, you should consider implementing it as a best practice.
Here, we create a user-assigned managed identity, assign appropriate blob permissions, and establish federated credentials. If your CI/CD platform doesn’t support OIDC federation, you can omit the managed identity and federated credentials resources, instead passing an app registration ID as a variable to role assigment or continuing to use the initial operator identity.
resource "azurerm_user_assigned_identity" "this" {
name = "cloudchronicles-init-msi"
location = azurerm_resource_group.this.location
resource_group_name = azurerm_resource_group.this.name
}
resource "azurerm_federated_identity_credential" "this" {
name = "GitHub-krukowskid-cloudchronicles-environment-prd"
resource_group_name = azurerm_resource_group.this.name
audience = ["api://AzureADTokenExchange"]
issuer = "https://token.actions.githubusercontent.com"
parent_id = azurerm_user_assigned_identity.this.id
subject = "repo:krukowskid/cloudchronicles:environment:prd"
}
resource "azurerm_role_assignment" "blob_data_contributor_msi" {
principal_id = azurerm_user_assigned_identity.this.principal_id
role_definition_name = "Storage Blob Data Contributor"
scope = azurerm_storage_account.this.id
skip_service_principal_aad_check = true
}
Automated migration
This is where the solution truly shines. We instruct Terraform to generate the missing configuration automatically by creating two files:
- A partial backend configuration file
- The backend configuration for Terraform itself
resource "local_file" "tfbackend" {
content = <<EOD
resource_group_name = "${azurerm_resource_group.this.name}"
storage_account_name = "${azurerm_storage_account.this.name}"
container_name = "${azurerm_storage_container.this.name}"
use_azuread_auth = true
EOD
filename = "../.config/${var.environment}.tfbackend"
}
resource "local_file" "backend" {
content = <<EOD
terraform {
backend "azurerm" {
key = "init.tfstate"
}
}
EOD
filename = "./backend.tf"
}
Step 3: Execution and State Migration
Execute the following commands to apply the configuration and transition to remote state storage. Remember to adjust the environment name in both prd.tfvars and prd.tfbackend to match your target environment:
cd ./path/to/terraform;
rm backend.tf;
terraform init;
terraform apply --var-file=./_parameters/prd.tfvars --auto-approve;
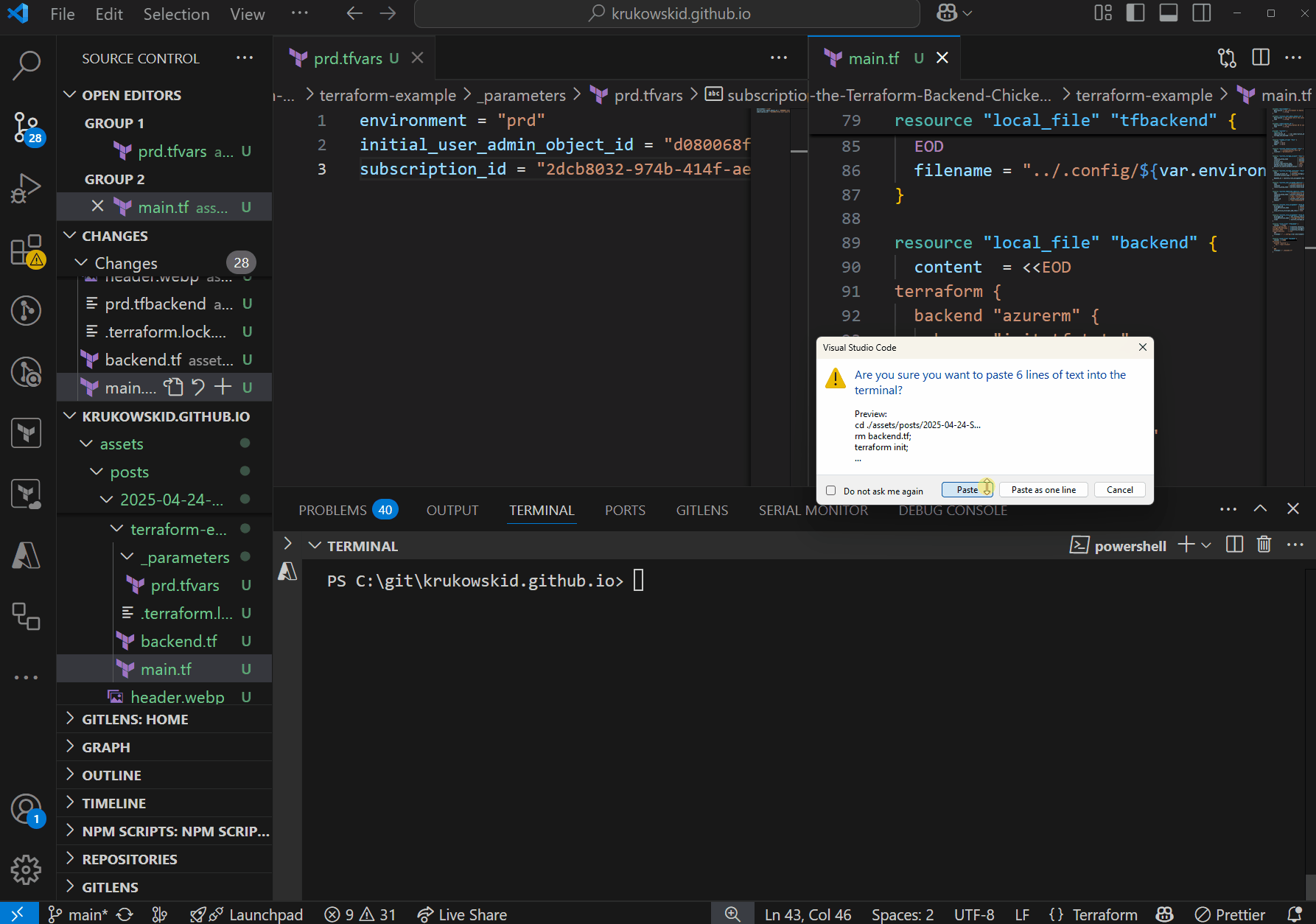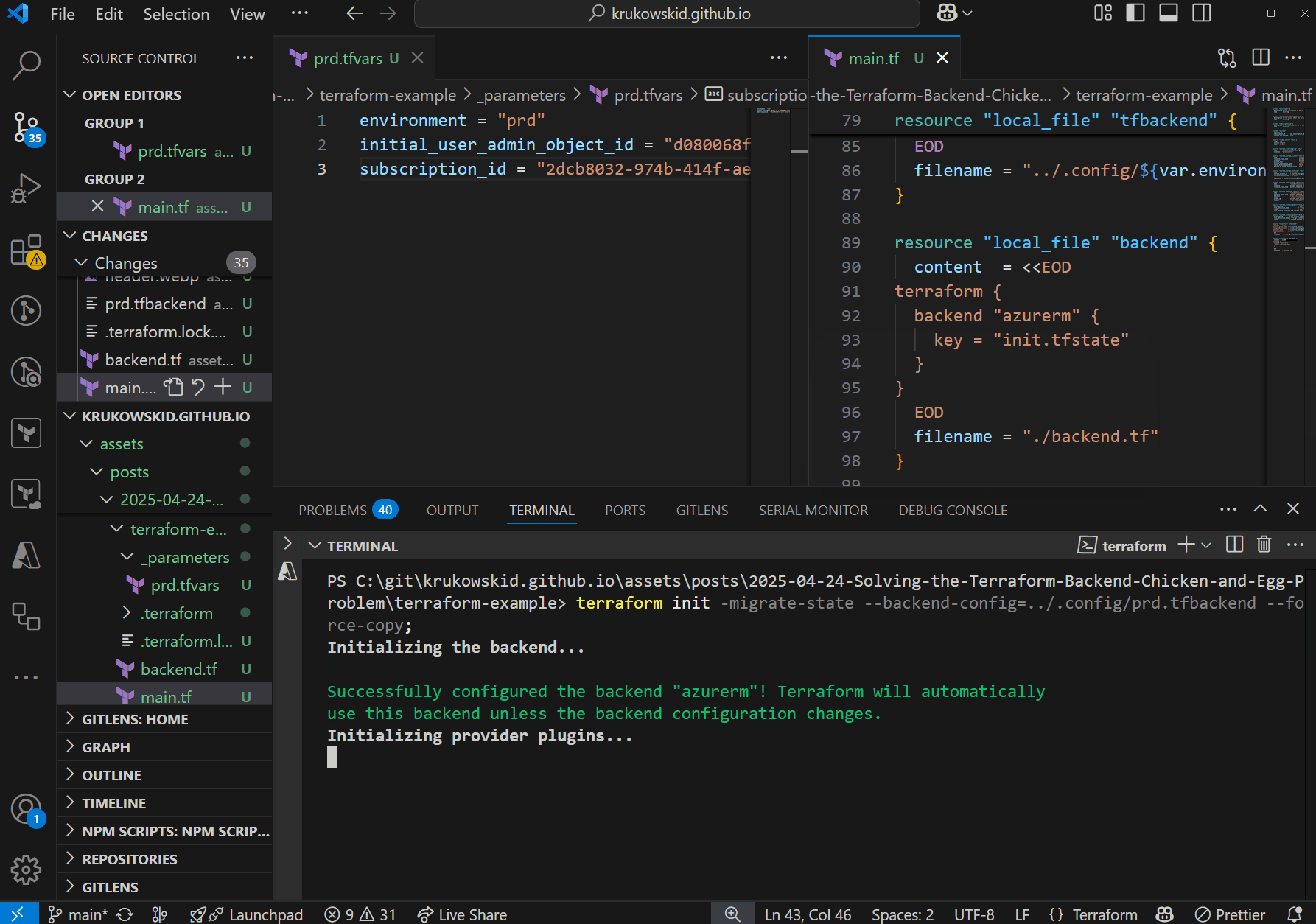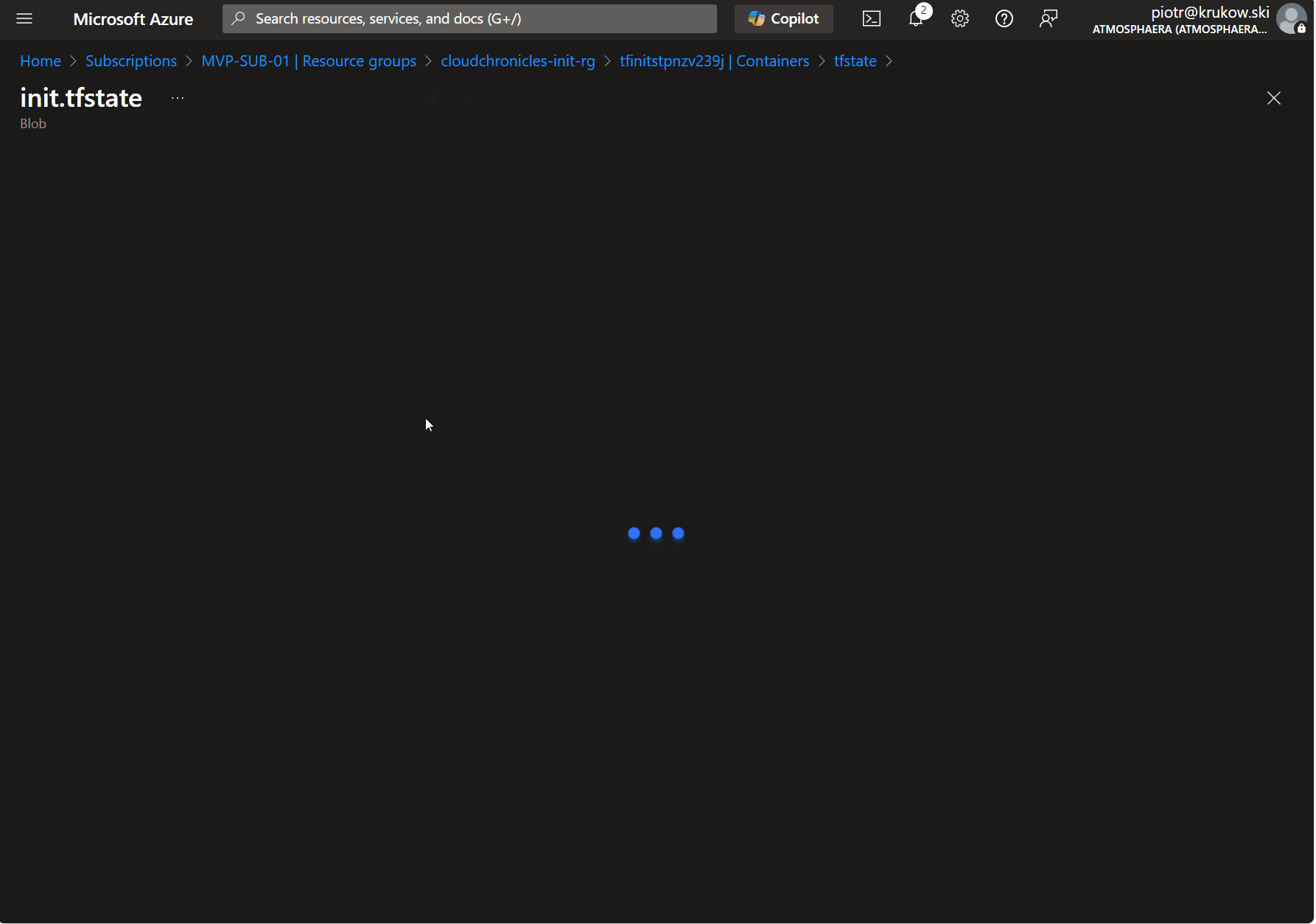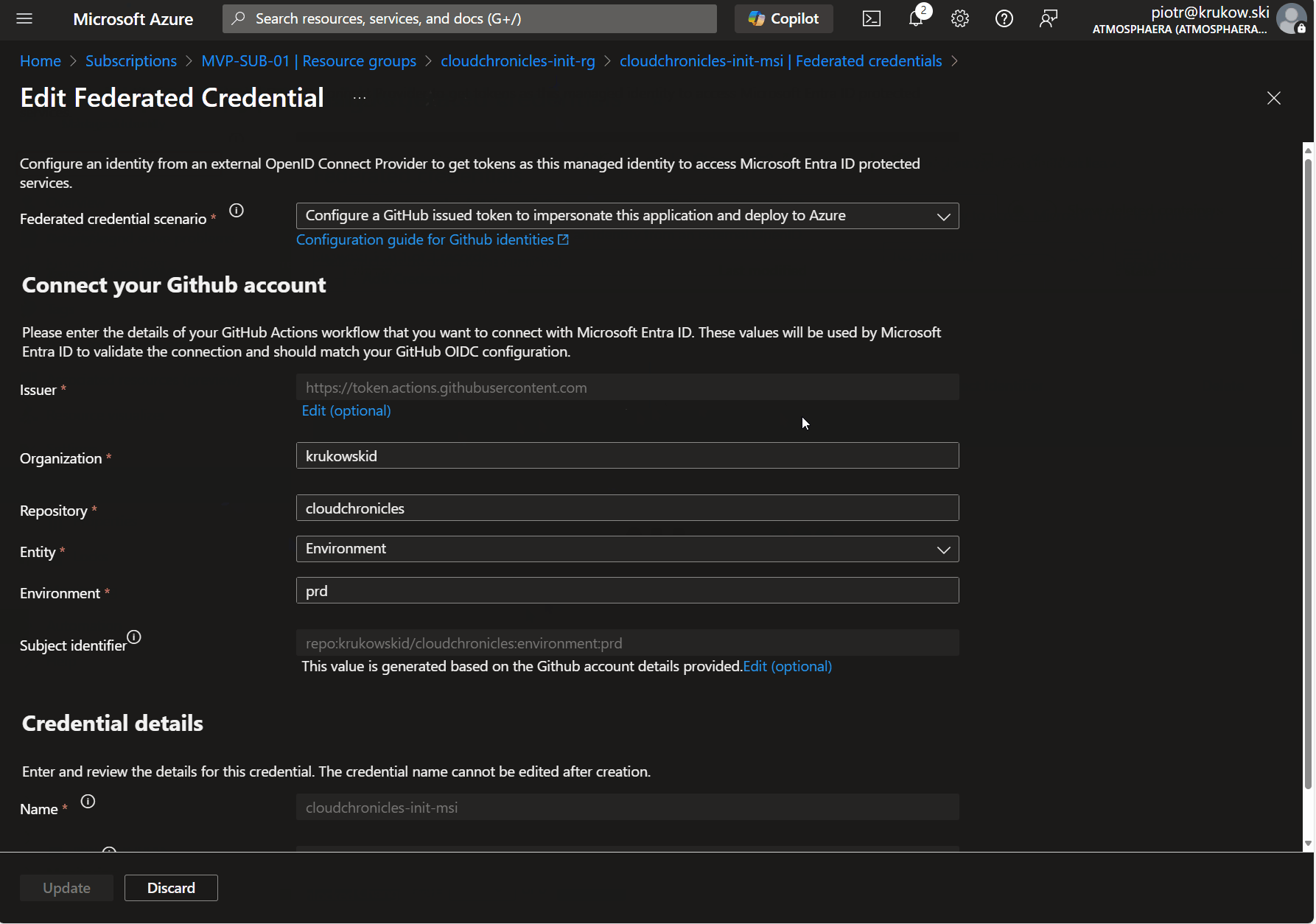
terraform init -migrate-state --backend-config=../.config/prd.tfbackend --force-copy
Sometimes the second init fails on lack of permissions because of delay in propagation on Azure side. If you encounter this error, simply re-run the last comand
This command sequence:
- Removes any existing backend.tf file to ensure we start with local state
- Initializes Terraform with local state storage
- Applies the configuration with auto-approval
- Executes another initialization with
-migrate-stateand--force-copyflags to transition to the backend specified in the auto-generated configuration files
Step 4: Commit files and switch to CI/CD
After migration, commit new *.tfbackend, *.tf and .terraform.lock.hcl files and manage state blob storage from the CI/CD.
Demo
You can find full code here: terraform-example