AKS Best Practices Part2: Cost Efficiency

- Introduction
- Core Infrastructure
- Cluster Configuration
- Other options
- Infrastructure and application architecture
Introduction
So you’ve made the switch from virtual machines or web app hosting to AKS. Everything seems fine until you see the bill at the end of the month. You start thinking, “Why does it cost me 900 bucks? Do I really need this?” While AKS itself isn’t expensive, the additional services and features can cost more than the cluster itself!
This is the second part of the series. You can read AKS Best Practices Part1: Availability Zones here.
Core Infrastructure
Virtual Machine Selection
Let’s start with the quantity, family, and size of VMs. These settings are often overlooked, yet you can significantly reduce costs by optimizing them - sometimes even with improved performance!
Generation and Family Selection
First, examine your VM generation. Older generations provide lower performance and are typically more expensive because Microsoft wants you to migrate to newer hardware to decommission the old ones - which is fair enough. You’ll need to check which machines are available in your region, because the offering vary between regions - you know, behind all those fancy portals, APIs and services there are physical datacenters with physical servers and infrastructure 😉
| DS3 v2 | D4as v5 | |
|---|---|---|
| vCPU | 4 | 4 |
| RAM | 14 GB | 16 GB |
| Price per month | 198$ | 167$ |
Price comparison for similar virtual machines in different generations in West Europe region
Once you’ve confirmed you’re on the newest generation, it’s time to consider the VM family. Ideally, you want to achieve a similar ratio of CPU to memory consumption.
If your application is memory-intensive (most web applications) and you’re using a D-series VM, you’ll likely notice that you’re maxing out your node memory resources while CPU usage hovers around 30%. 
In this case, you can either:
- Use a larger size of the same machine
- Scale out to another node
- Switch to E-Series VMs, which provide a higher memory-to-CPU ratio and help better utilize your resources
RAM is not your issue? You can use F-Series VMs if you’re constantly getting throttled by node CPU limitations while underutilizing memory resources.
If you’re running a large number of pods in your cluster, you might benefit from using multiple nodepools with different VM types . Then you can group your workloads to ensure each pod is running on the best VM type by using Kubernetes capabilities like taints, tolerations, labels, and priorities to better utilize your resources. However, for clusters with just a few nodes, this complexity might not be worth it.
Intel, AMD, or ARM?
Looking at price charts, you’ll notice that VMs with ARM architecture (Ampere and Cobalt) are noticeably cheaper. However, to run your application on ARM, you’ll need to build it specifically for that architecture. While this might be worth considering for clusters with hundreds to thousands of nodes, the development effort required for tooling, build and testing processes, and developer workstation setup may outweigh the savings for smaller deployments.
In most cases, AMD-based VMs offer a cost-effective alternative, generally being cheaper than equivalent Intel machines while often providing slightly better performance.
| D4s v5 (Intel) | D4as v5 (AMD) | |
|---|---|---|
| vCPU | 4 | 4 |
| Memory | 16 GB | 16 GB |
| Performance score | 671141 | 729282 |
| Price per month | 167$ | 151$ |
Price comparison for same machine with Intel and AMD CPU
There are edge cases with virtualization and Intel-optimized applications where Intel CPUs would perform better, but for generic workloads, you can safely use the cheaper option. You can identify the processor type by looking at the VM name:
-
a- AMD -
p- ARM - neither
aorp- Intel
Storage Configuration
Ephemeral Disks
This is my favorite optimization because VMs with ephemeral disks present an interesting cost paradox - they’re often more expensive but ultimately cheaper! This occurs because using ephemeral OS disks requires a VM with a temporary disk, and such VMs are more expensive compared to ones without attached storage. However, if your VM type doesn’t support ephemeral disks, you’re forced to attach a managed disk, which comes with its own cost - often higher than the combined cost of a temporary disk and the VM itself.
VMs with the d in the name include a temporary disk. You might wonder about the meaning of “ephemeral disk”. These disks aren’t meant for persistent data storage. However, since clusters aren’t meant for persistent data storage either - all data should be stored in databases, storage accounts, or persistent volumes - ephemeral disks are perfect for AKS OS disks.
Small VMs and ephemeral disks
By default, the ephemeral disk size is set to 128GB. When using ephemeral disks with smaller VMs, you’ll need to adjust the OS disk size to match the temporary disk limit (minus 1GB if using trusted launch). For example, with a D2ads_v5, you can set a 75GB ephemeral disk (74GB when using trusted launch). Any size above 30GB will work effectively for Linux OS if not using emptyDirs.
To specify smaller os disk size in Terraform, you need to specify following parameters:
resource "azurerm_kubernetes_cluster" "this" {
...
os_disk_size_gb = 74
os_disk_type = "Ephemeral"
default_node_pool {
...
vm_size = "Standard_D2ads_v2"
}
...
}
If you don’t specify the OS disk size for Standard_D2ads_v2 and try to create node pool with ephemeral OS disk, you will get an error.
The default logic follows these rules:
- If the VM SKU supports ephemeral disks and has sufficient cache size or temp storage, ephemeral becomes the default OS disk
- If the VM SKU doesn’t support ephemeral disks, Premium SSD becomes the default OS disk
- If neither of the above applies, Standard SSD becomes the default OS disk
Larger disks have better performance, so with managed disk you should use larger disk with bigger nodes.
Persistent Storage
When running in Azure, persistent volume claims are typically backed by Azure Disks or Azure Files. Even in environments where persistent volumes are minimal, I’ve encountered many clusters with dozens of overprovisioned disks - both in terms of space and SKU selection. While the per-GB pricing is similar for both Disks and Files, their billing models differ significantly:
Azure Disks:
- You pay for the requested space, regardless of actual usage
- Performance scales with both SKU and disk size - often requiring larger disks just to meet performance needs
- Only one AKS node can mount a disk at a time - Multiple service replicas require multiple disks, which may unnecessarily increase costs
Azure Files:
- Pay only for used space, not requested capacity
- Performance is determined solely by SKU (Standard or Premium)
- Supports simultaneous mounting across multiple nodes and pods
- Offers native mechanisms for file access and backup
Tips
Evaluate your storage needs:
- For temporary files used only during pod lifetime, consider using EmptyDir (can utilize node disk or memory)
- For persistent data, verify you’re using the appropriate SKU
Review your current setup:
- Can you use smaller disks?
- Would moving to Azure Files benefit your workload?
- Are you using multiple disks where a single Azure Files share would suffice?
Regions
Regional price differences can be substantial - you might find up to 100% price variation for identical resources across regions! Choose your regions strategically,. If you’re heavily integrated with one region, carefully evaluate the benefits of multi-region expansion for cost reduction, especially for non-production environments where data location and additional milliseconds of latency are often acceptable.
| West Europe | Switzerland North | |
|---|---|---|
| Price per month | 151$ | 179$ |
Price comparison for D4as v5 virtual machines in two different regions
Cross-Region Considerations and Networking
Cross-zone data transfer within same Azure region is free. However, placing AKS and linked resources in different regions will have a significant impact on your bill due to cross-region data transfer costs. For example, using a geo-replicated database with the primary instance in another region incurs additional costs.
For multi-zone clusters using managed disks (for example persistent volumes), your disks will automatically be created as ZRS (Zone-Redundant Storage) disks, which cost approximately 1.5x more than LRS (Locally Redundant Storage) disks.
Cluster Configuration
Operating System Selection
From experience and official information, Azure Linux typically consumes slightly less resources, because it is optimized for the Azure and trimmed down to only necessary packages. If you’re looking to maximize node utilization, consider switching to Azure Linux. Always test your applications after switching, though there’s a small chance of compatibility issues (I’ve never encountered any personally, but seen some issues on GitHub).
From version AKS 1.31 you can use newest version Azure Linux 3.0 in preview. From 1.32 this will be released as GA5
Load Balancer and API SKU
While I won’t delve into Load Balancer SKUs (since the basic tier will be retired in September 2025), you can optimize costs by selecting the appropriate cluster management service tier. The three cluster management tiers are:
- Premium (~$438/month): Needed for extended (LTS) support of outdated AKS versions
- Standard (~$73/month): Provides financially backed SLA with refunds for service failures
- Free: Suitable for up to 1000 nodes with lower API call limits
Both Premium and Standard support up to 5000 nodes. The Free tier is recommended for clusters up to 10 nodes and non-business-critical workloads however, you can deploy up to 1000 nodes and use it without an issue if you don’t hit Kubernetes API limit. You can easily upgrade tiers after cluster creation, so starting with Free tier and scaling up as needed is a good idea for non-production clusters, and production with moderate load where you can accept the limitations and lack of the SLA.
AKS Version and Right-Sizing Max Pods per Node
A significant change arrived with version 1.29 regarding kubelet memory reservation6. Prior to 1.29, there was an eviction rule maintaining at least 750Mi of allocatable memory at all times, plus memory reservations of:
- 25% of the first 4 GB of memory
- 20% of the next 4 GB of memory (up to 8 GB)
- 10% of the next 8 GB of memory (up to 16 GB)
- 6% of the next 112 GB of memory (up to 128 GB)
- 2% of any memory above 128 GB
For example, on an 8GB node before 1.29:
\(4GB * 0.75 (kube-reserved) + 4GB * 0.8 (kube-reserved) - 0.75GB (eviction threshold) = 5.45GB\)
From 1.29 onward, the kubelet eviction threshold is reduced from 750Mi to 100Mi, and memory reservation follows the lesser of:
- 20 MB * Max Pods supported on the Node + 50 MB
- 25% of total system memory resources
This makes it important to set appropriate max pod limits on your nodes based on your workload. For example, with a 30-pod limit on an 8GB node:
\(20 MB * 30 Max Pods + 50 MB = 650 MB for kube-reserved\).
\(8 GB - 0.65 GB (kube-reserved) - 0.1 GB (eviction threshold) = 7.25 GB\)
By simply upgrading to the newer version and setting appropriate pod limits, you can gain an additional 1.8GB of node RAM.
Bigger and fewer nodes vs smaller and more nodes
Taking into consideration that AKS reserve some amount of memory for every node, the number of your pods and workload specific data, you need to decide if you want to use more smaller nodes, or fewer bigger nodes in your cluster. Using bigger nodes will give you bit more memory and CPU available, but also can lead to underutilised node after scale-up action.
Here is a great a write up on this exact topic: Architecting Kubernetes clusters — choosing a worker node size which will help you make a call on right size.
Memory/CPU limits
Setting appropriate pod requests and limits helps optimize resource utilization. Review your current configuration carefully, especially if you’re managing dozens of nodes and hundreds of pods. Main point here are memory/CPU requests. If you set it too high, you will waste node resources by reserving specified amount of compute resources exclusively for pod. For CPU I usually don’t recommend setting limits because it’s often leads to CPU throttling on a service and lower performance and provide no benefits.
If you don’t know how to properly setup those values, start with the KRR tool, which will help you get baseline values or optimize existing ones.
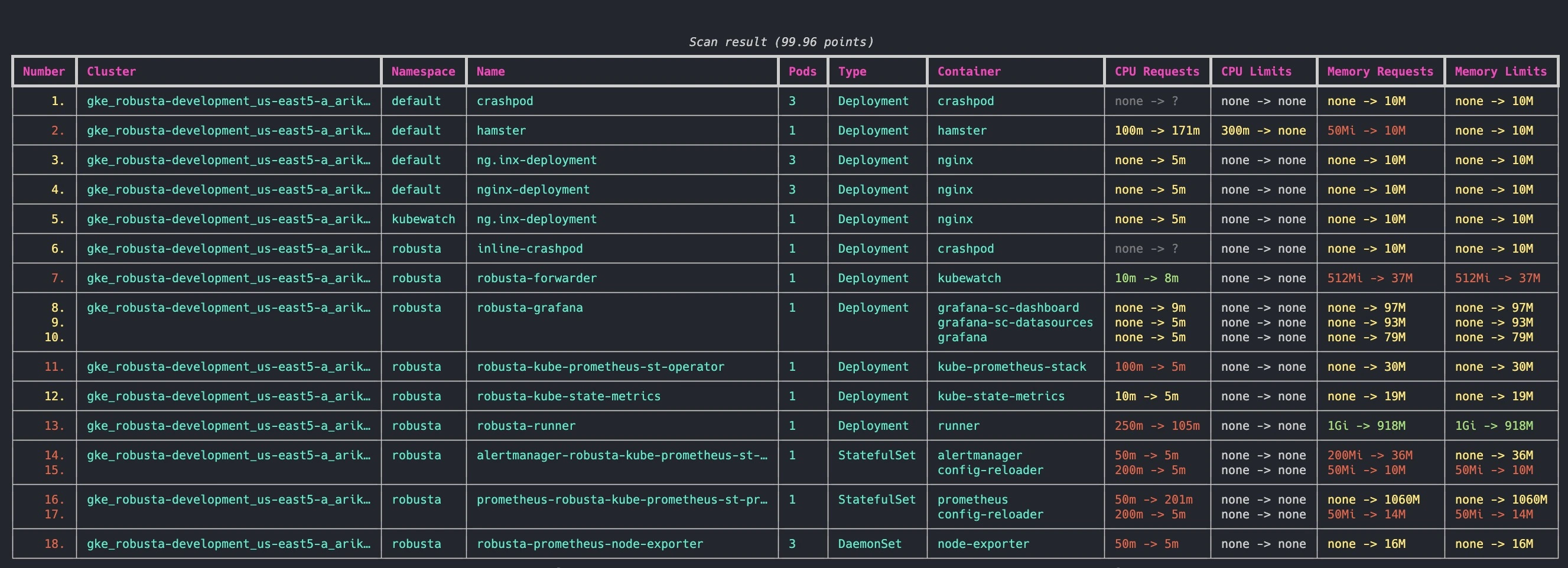 KRR tool dashboard
KRR tool dashboard
Logs and metrics
Turning on logs, metrics, traces is easy in AKS, but it will lead to a situation where your logs will cost you more than infrastructure itself. From my experience you don’t need 95% of ingested data “just in case”. I saw logs with PII, logs that something was logged, logs that nothing was fetched in a loop that is running every second or logs for every get, no matter if its internal, healtcheck probe or external. In practice, a significant portion of this logged data provides minimal value. If it’s possible then setup a logging, and add logs and metrics that are important for you instead of saving everything just in case.
If you already logging everything, there is great a writeup on how to limit those cost https://trstringer.com/log-analytics-expensive-part-1-discovery/ https://trstringer.com/log-analytics-expensive-part-2-save/
You might consider moving data from Log Analytics to Blob Storage, or hosting your own monitoring stack, or mix those options. Hosting your own stack might come with a lot of hidden costs - because you need to deploy, maintain, and of course host it somewhere.
In dotnet projecs running only on Azure I was often using mix of Grafana + Loki and Azure Monitor capabilities with proper configuration both on cluster and application level. In those with mixed languages and environment types, full grafana stack, without Azure native components.
If you want to fine tune monitoring related settings, most of them are configured in container-azm-ms-agentconfig ConfigMap.
For example, if you decide to use Loki for logs, but Azure for other things, you can create config map like this
data:
schema-version: v1
config-version: v1
log-data-collection-settings: |-
[log_collection_settings]
[log_collection_settings.stdout]
enabled = false
exclude_namespaces = ["kube-system"]
[log_collection_settings.stderr]
enabled = false
exclude_namespaces = ["kube-system"]
[log_collection_settings.env_var]
enabled = false
which will disable collecting logs from all namespaces but kube-system. Of course changing things only at the infrastructure level is not a way to go - adjust your log levels in application and ensure that it logs valuable information.
You can find more informations in below links
https://learn.microsoft.com/en-us/azure/azure-monitor/containers/container-insights-data-collection-configure https://learn.microsoft.com/en-us/azure/azure-monitor/containers/container-insights-data-collection-filter
Retention
It is super important to set up retention on your logs and metrics. If you are not in regulated industry, you don’t need to store your logs for an infinite time. If you are working in regulated industry, you don’t need to keep them for inifinite time too. You can setup multiple retention rules to comply with the requirements and keep audit logs for years, while removing traces or application error logs every few days.
Your retention time should be setup to the level where logs are still valuable for you. Personally, when it comes to logs which are set only for debugging purposes I’ve set retention to no more than 30 days.
If you need to keep your logs for excessive period of time, you can offload old logs to cheaper storage like Azure Blob in Cold/Archive Tier.
Other options
Cluster Shutdown
You can stop your cluster during inactive periods (nights, weekends) to reduce costs. With no managed disks for OS or PVC, this completely eliminates costs during downtime. For faster recovery, consider scaling user pools to 0 while maintaining the system pool with cost savings or reserved instances and scaling it down as well.
The start/stop operation may change the Kubernetes API IP address7
so implement a dynamic DNS resolution mechanism (like a DNS forwarder) if using a private cluster. For a simple start/stop solution, create a pipeline in your preferred CI/CD platform (GitHub, Azure DevOps, GitLab) with:
- Cron trigger for scheduled operations
- Manual trigger option for team members
- Ability to disable automatic shutdown when needed
Some applications don’t handle shutdowns really well. Test it thoroughly and adjust your application code or start/stop mechanism to handle such event.
Spot VMs
While I’m enthusiastic about the Karpenter project and eagerly awaited its release, my initial testing revealed numerous issues. Currently, it’s best suited for workloads that can handle evictions and minor disruptions, rather than general workloads requiring predictable behavior. Fortunately, there’s a native alternative combining cluster autoscaler with spot virtual machines. I’ve used this combination successfully for three years with excellent out-of-box performance.
For production use, some fine-tuning is necessary, varying by workload. Key considerations include:
- Ensuring critical pods run on standard nodes (protecting against spot evictions)
- Managing unpredictable pod evictions (spot instances can be evicted with 30 seconds notice8)
From experience, if you don’t set overly restrictive spot price limits, nodes can run continuously for months! Here’s a reliable configuration for non-production environments:
Nodepool configuration:
resource "azurerm_kubernetes_cluster_node_pool" "this" {
kubernetes_cluster_id = azurerm_kubernetes_cluster.this.id
name = "spot01"
...
priority = "Spot"
eviction_policy = "Delete"
spot_max_price = -1
node_labels = { kubernetes.azure.com/scalesetpriority = "spot" }
node_taints = ["kubernetes.azure.com/scalesetpriority=spot:NoSchedule"]
...
}
The spot VMs pricing is dynamic depending on the demand. Although-1 max price means that there is no price limit for the spot instance, you won’t even get close to the standard price.
Service tolerations:
tolerations:
- key: kubernetes.azure.com/scalesetpriority
operator: "Equal"
value: "spot"
effect: "NoSchedule"
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "kubernetes.azure.com/scalesetpriority"
operator: NotIn
values:
- "spot"
Cluster autoscaler config map:
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-autoscaler-priority-expander
namespace: kube-system
data:
priorities: |-
100:
- .*spot.*
10:
- .*
Higher number means higher priority. It looks by the node pool name, so you need to ensure that your spot pool name contains spot in its name or adjust the config map.
After configuring autoscaler config map, you also need set it to use priority expander
resource "azurerm_kubernetes_cluster" "this" {
...
auto_scaler_profile {
expander = "priority"
}
...
}
If you would like to test out how your system behaves during the spot node eviction, you can force it by running following command
az vmss simulate-eviction --resource-group MyResourceGroup --name MyScaleSet --instance-id 0
or an api call
POST https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Compute/virtualMachineScaleSets/{vmScaleSetName}/virtualMachines/{instanceId}/simulateEviction?api-version=2024-07-01
Reservations and saving plans
Since AKS nodes are essentially virtual machines running in a scale set, both reservations and savings plans apply. Take advantage of these cost-optimization options when possible.
You can find more information here:
Private DNS
If you are fighting for every dollar, you can use public Azure DNS for cluster IP resolving in private cluster.
After setting in Terraform:
resource "azurerm_kubernetes_cluster" "this" {
...
private_dns_zone_id = "None"
private_cluster_public_fqdn_enabled = true
...
}
Your cluster will be provisioned without private DNS zone, the record will be created in public DNS which translates to about 0.5-1$ per month in saving! Besides monetary benefits it’s a great option for simplifying Kube Api DNS resolution for private cluster if allowing to resolve private IP from the Internet isn’t an issue (in most workloads is not, but PCI Standards require to hide it)
Infrastructure and application architecture
This often presents the biggest opportunity for cost savings, though it’s typically the most challenging and expensive to implement. Unfortunately, there’s no one-size-fits-all solution, but here are some areas to consider:
From an application perspective:
- If you’re hosting workloads for multiple clients (tenants) with separate services for each, consider refactoring to shared services with tenant logic to reduce compute resources
- Evaluate whether moving services into or out of containers would be beneficial
- Look for opportunities to replace custom services with managed alternatives (or managed with custom) - for example move a queue service running in the cluster that is using PVC and cluster resources to Service Bus
From an infrastructure perspective:
- Check if you’re running services on VMs that could be moved into your AKS cluster
- Consider whether moving from AKS to Azure Container Apps or other services would be more cost-effective (or another way from ACA/Web Apps to AKS). Consider not only Azure resources cost but also maintenance cost.
- Evaluate your overall architecture for consolidation opportunities - merging multiple clusters into one with namespace separation
If you need guidance on optimizing your infrastructure and application architecture, feel free to connect with me on LinkedIn.
https://learn.microsoft.com/en-us/azure/virtual-machines/disks-change-performance ↩︎
https://learn.microsoft.com/en-us/azure/storage/files/understand-performance ↩︎
https://techcommunity.microsoft.com/blog/linuxandopensourceblog/azure-linux-3-0-now-in-preview-on-azure-kubernetes-service-v1-31/4287229 ↩︎
https://learn.microsoft.com/en-us/azure/aks/node-resource-reservations#memory-reservations ↩︎
https://learn.microsoft.com/en-us/azure/aks/start-stop-cluster ↩︎
https://learn.microsoft.com/en-us/azure/architecture/guide/spot/spot-eviction ↩︎
